第二十八章
高級 OpenGL • 實例化
假設一個場景中,你要繪製許多模型,而這些模型中的大部分都包含相同的頂點資料,只是世界座標變換(world transformations)不同。想像一個長滿草葉的場景:每一片草葉都是一個由幾個三角形組成的小模型。你可能會想畫很多片草葉,而你的場景最後可能會需要每幀渲染成千上萬,甚至上萬片的草葉。因為每一片葉子都只有幾個三角形,所以單獨繪製一片葉子幾乎是瞬間完成。然而,你必須進行數千次的繪製呼叫(render calls),這會大幅降低效能。
如果我們真的要渲染如此大量的物體,程式碼看起來會像這樣:
for(unsigned int i = 0; i < amount_of_models_to_draw; i++)
{
DoSomePreparations(); // bind VAO, bind textures, set uniforms etc.
glDrawArrays(GL_TRIANGLES, 0, amount_of_vertices);
}
當像這樣繪製模型的許多「實例(instances)」時,由於大量的繪製呼叫,你很快就會遇到效能瓶頸。與實際渲染頂點相比,用 glDrawArrays 或 glDrawElements 函式告訴 GPU 渲染你的頂點資料會佔用相當多的效能,因為 OpenGL 必須在繪製頂點資料之前進行必要的準備工作(例如,告訴 GPU 從哪個緩衝區讀取資料、在哪裡找到頂點屬性,以及所有這些都透過相對較慢的 CPU 到 GPU 匯流排來完成)。所以,儘管渲染頂點本身超級快,但給 GPU 下達渲染它們的命令卻不是。
如果我們可以將資料一次性發送到 GPU,然後告訴 OpenGL 用一次繪製呼叫來繪製多個使用這些資料的物件,那將會方便得多。這就是「實例化(instancing)」的登場時機。
實例化是一種技術,我們可以用一次繪製呼叫來一次性繪製許多(網格資料相同)的物件,省去了每次需要渲染一個物件時所產生的所有 CPU -> GPU 通訊。要使用實例化進行渲染,我們所需要做的就是將渲染呼叫 glDrawArrays 和 glDrawElements 分別更改為 glDrawArraysInstanced 和 glDrawElementsInstanced。這些「實例化」版本的經典渲染函式會多一個名為 instance count 的額外參數,用於設定我們想要渲染的實例數量。我們將所有需要的資料一次性發送給 GPU,然後用一次呼叫告訴 GPU 應該如何繪製所有這些實例。接著,GPU 會渲染所有這些實例,而無需持續與 CPU 通訊。
單獨來看,這個功能有點沒用。將同一個物件渲染一千次對我們來說沒有任何意義,因為每個被渲染的物件都完全相同,因此也都在同一個位置;我們只會看到一個物件!為此,GLSL 在頂點著色器中增加了一個名為 gl_InstanceID 的內建變數。
當使用實例化渲染呼叫之一進行繪製時,gl_InstanceID 會隨著每個被渲染的實例而遞增,從 0 開始。舉例來說,如果我們正在渲染第 43 個實例,那麼在頂點著色器中 gl_InstanceID 的值將會是 42。每個實例都有一個獨特的值,這意味著我們現在可以索引到一個大型的位置值陣列中,從而將每個實例定位在世界中的不同位置。
為了對實例化繪製有感覺,我們將演示一個簡單的範例,它只用一個渲染呼叫,在標準化裝置座標(normalized device coordinates)中渲染一百個 2D 四邊形。我們透過索引一個包含 100 個位移向量的 uniform 陣列,來為每個實例化的四邊形進行獨特的定位。結果是一個整齊排列、填滿整個視窗的四邊形網格:
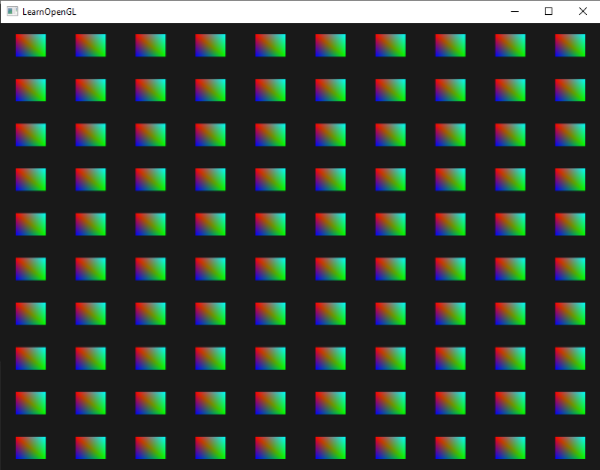
每個四邊形由 2 個三角形組成,總共有 6 個頂點。每個頂點包含一個 2D 的 NDC 位置向量和一個顏色向量。以下是用於此範例的頂點資料——當有 100 個四邊形時,這些三角形足夠小,可以適當地填滿螢幕:
float quadVertices[] = {
// positions // colors
-0.05f, 0.05f, 1.0f, 0.0f, 0.0f,
0.05f, -0.05f, 0.0f, 1.0f, 0.0f,
-0.05f, -0.05f, 0.0f, 0.0f, 1.0f,
-0.05f, 0.05f, 1.0f, 0.0f, 0.0f,
0.05f, -0.05f, 0.0f, 1.0f, 0.0f,
0.05f, 0.05f, 0.0f, 1.0f, 1.0f
};
四邊形是在片段著色器中著色的,片段著色器從頂點著色器接收一個顏色向量,並將其設為它的輸出:
#version 330 core
out vec4 FragColor;
in vec3 fColor;
void main()
{
FragColor = vec4(fColor, 1.0);
}
到目前為止還沒有什麼新東西,但在頂點著色器中,事情開始變得有趣了:
#version 330 core
layout (location = 0) in vec2 aPos;
layout (location = 1) in vec3 aColor;
out vec3 fColor;
uniform vec2 offsets[100];
void main()
{
vec2 offset = offsets[gl_InstanceID];
gl_Position = vec4(aPos + offset, 0.0, 1.0);
fColor = aColor;
}
在這裡我們定義了一個名為 offsets 的 uniform 陣列,其中包含了總共 100 個位移向量。在頂點著色器中,我們透過使用 gl_InstanceID 來索引 offsets 陣列,從而為每個實例取得一個位移向量。如果我們現在要用實例化繪製來繪製 100 個四邊形,我們就會得到 100 個位於不同位置的四邊形。
我們確實需要在進入渲染迴圈之前,在一個巢狀 for 迴圈中計算並設定這些位移位置:
glm::vec2 translations[100];
int index = 0;
float offset = 0.1f;
for(int y = -10; y < 10; y += 2)
{
for(int x = -10; x < 10; x += 2)
{
glm::vec2 translation;
translation.x = (float)x / 10.0f + offset;
translation.y = (float)y / 10.0f + offset;
translations[index++] = translation;
}
}
在這裡我們建立了一組 100 個的平移向量,其中包含 10x10 網格中所有位置的位移向量。除了產生 translations 陣列之外,我們還需要將資料傳輸到頂點著色器的 uniform 陣列中:
shader.use();
for(unsigned int i = 0; i < 100; i++)
{
shader.setVec2(("offsets[" + std::to_string(i) + "]")), translations[i]);
}
在這段程式碼中,我們將 for 迴圈計數器 i 轉換為 string,以動態地建立一個用於查詢 uniform 位置的位置字串。然後,我們為 offsets uniform 陣列中的每個項目設定對應的平移向量。
現在所有準備工作都已完成,我們可以開始渲染四邊形了。要透過實例化渲染進行繪製,我們呼叫 glDrawArraysInstanced 或 glDrawElementsInstanced。由於我們沒有使用元素索引緩衝區,因此我們將呼叫 glDrawArrays 版本:
glBindVertexArray(quadVAO);
glDrawArraysInstanced(GL_TRIANGLES, 0, 6, 100);
glDrawArraysInstanced 的參數與 glDrawArrays 完全相同,除了最後一個參數,它設定了我們想要繪製的實例數量。因為我們想要在 10x10 的網格中顯示 100 個四邊形,所以我們將其設定為等於 100。執行程式碼後,你應該會得到那張熟悉的,包含 100 個彩色四邊形的圖片。
實例化陣列(Instanced arrays)
儘管先前的實作對於這個特定的用例運作良好,但當我們渲染的實例數量遠超過 100 個(這很常見)時,我們最終會達到可以發送到著色器的 uniform 資料量的 限制。另一種選擇被稱為「實例化陣列(instanced arrays)」。實例化陣列被定義為一種頂點屬性(允許我們儲存更多的資料),它會「每個實例」而不是「每個頂點」更新一次。
對於頂點屬性,在頂點著色器的每次執行開始時,GPU 會取得屬於當前頂點的下一組頂點屬性。然而,當將頂點屬性定義為實例化陣列時,頂點著色器只會「每個實例」更新一次頂點屬性的內容。這使我們能夠使用標準的頂點屬性來處理每個頂點的資料,並使用實例化陣列來儲存每個實例獨有的資料。
為了給您一個實例化陣列的範例,我們將沿用先前的範例,並將位移 uniform 陣列轉換為實例化陣列。我們必須透過添加另一個頂點屬性來更新頂點著色器:
#version 330 core
layout (location = 0) in vec2 aPos;
layout (location = 1) in vec3 aColor;
layout (location = 2) in vec2 aOffset;
out vec3 fColor;
void main()
{
gl_Position = vec4(aPos + aOffset, 0.0, 1.0);
fColor = aColor;
}
我們不再使用 gl_InstanceID,而是可以直接使用 offset 屬性,而無需先索引到一個大型 uniform 陣列中。
因為實例化陣列是一個頂點屬性,就像 position 和 color 變數一樣,我們需要將其內容儲存在頂點緩衝物件(vertex buffer object)中,並配置它的屬性指標(attribute pointer)。我們首先將 translations 陣列(來自前一節)儲存到一個新的緩衝物件中:
unsigned int instanceVBO;
glGenBuffers(1, &instanceVBO);
glBindBuffer(GL_ARRAY_BUFFER, instanceVBO);
glBufferData(GL_ARRAY_BUFFER, sizeof(glm::vec2) * 100, &translations[0], GL_STATIC_DRAW);
glBindBuffer(GL_ARRAY_BUFFER, 0);
然後我們還需要設定它的頂點屬性指標並啟用頂點屬性:
glEnableVertexAttribArray(2);
glBindBuffer(GL_ARRAY_BUFFER, instanceVBO);
glVertexAttribPointer(2, 2, GL_FLOAT, GL_FALSE, 2 * sizeof(float), (void*)0);
glBindBuffer(GL_ARRAY_BUFFER, 0);
glVertexAttribDivisor(2, 1);
這段程式碼有趣的地方在於我們呼叫 glVertexAttribDivisor 的最後一行。這個函式告訴 OpenGL 何時將頂點屬性的內容更新到下一個元素。它的第一個參數是要處理的頂點屬性,第二個參數是 attribute divisor。預設情況下,屬性除數是 0,這告訴 OpenGL 在頂點著色器的每次迭代中更新頂點屬性內容。透過將此屬性設為 1,我們是在告訴 OpenGL,當我們開始渲染一個新實例時,我們想要更新頂點屬性的內容。如果將其設為 2,我們將每隔 2 個實例更新一次內容,以此類推。透過將屬性除數設為 1,我們有效地告訴 OpenGL,屬性位置 2 的頂點屬性是一個實例化陣列。
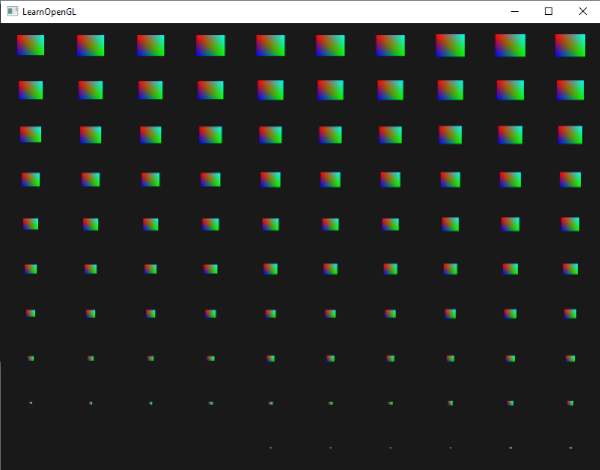
如果我們現在再次使用 glDrawArraysInstanced 來渲染四邊形,我們會得到以下輸出:
這與先前的範例完全相同,但現在使用了實例化陣列,這使我們能夠將更多的資料(多到記憶體允許的範圍)傳遞給頂點著色器,以進行實例化繪製。
為了好玩,我們也可以再次使用 gl_InstanceID,從右上到左下慢慢縮小每個四邊形,何樂而不為呢?
void main()
{
vec2 pos = aPos * (gl_InstanceID / 100.0);
gl_Position = vec4(pos + aOffset, 0.0, 1.0);
fColor = aColor;
}
結果是,最前面的幾個實例(instances)的四邊形被繪製得非常小,而當我們在繪製實例的過程中越往後,gl_InstanceID 就越接近 100,因此四邊形也越能恢復到它們原始的大小。像這樣將實例化陣列(instanced arrays)與 gl_InstanceID 一起使用是完全合法的。
如果您對於實例化渲染的工作方式仍然有點不確定,或者想看看所有東西是如何組合在一起的,您可以在這裡找到完整的應用程式原始碼。
雖然很有趣,但這些例子並不是實例化的絕佳範例。是的,它們確實為您提供了實例化工作原理的簡單概述,但實例化的大部分威力在於繪製大量相似的物件時才能發揮出來。出於這個原因,我們將冒險進入太空。
小行星帶
想像一個場景,我們有一個巨大的行星,它位於一個大型小行星環的中心。這樣一個小行星環可能包含數千或數萬個岩石結構,並且很快就會讓任何不錯的顯示卡都難以渲染。這種場景證明了實例化渲染特別有用,因為所有小行星都可以用一個單一模型來表示。然後,每個單獨的小行星都從一個獨屬於它自己的變換矩陣中獲得變化。
為了展示實例化渲染的影響,我們將首先不使用實例化渲染來渲染一個圍繞行星盤旋的小行星場景。該場景將包含一個可以從這裡下載的巨大行星模型,以及一組我們適當放置在行星周圍的大量小行星岩石。小行星岩石模型可以從這裡下載。
在程式碼範例中,我們使用之前在模型載入(model loading)章節中定義的模型載入器來載入模型。
為了達到我們想要的效果,我們將為每個小行星生成一個模型變換矩陣。變換矩陣首先將岩石平移到小行星環的某個地方——然後我們將向位移(offset)添加一個小的隨機位移值,使星環看起來更自然。從那裡我們還應用一個隨機的縮放和隨機的旋轉。結果是一個變換矩陣,它將每個小行星平移到行星周圍的某個位置,同時與其他小行星相比,也賦予了它更自然和獨特的外觀。
unsigned int amount = 1000;
glm::mat4 *modelMatrices;
modelMatrices = new glm::mat4[amount];
srand(glfwGetTime()); // initialize random seed
float radius = 50.0;
float offset = 2.5f;
for(unsigned int i = 0; i < amount; i++)
{
glm::mat4 model = glm::mat4(1.0f);
// 1. translation: displace along circle with 'radius' in range [-offset, offset]
float angle = (float)i / (float)amount * 360.0f;
float displacement = (rand() % (int)(2 * offset * 100)) / 100.0f - offset;
float x = sin(angle) * radius + displacement;
displacement = (rand() % (int)(2 * offset * 100)) / 100.0f - offset;
float y = displacement * 0.4f; // keep height of field smaller compared to width of x and z
displacement = (rand() % (int)(2 * offset * 100)) / 100.0f - offset;
float z = cos(angle) * radius + displacement;
model = glm::translate(model, glm::vec3(x, y, z));
// 2. scale: scale between 0.05 and 0.25f
float scale = (rand() % 20) / 100.0f + 0.05;
model = glm::scale(model, glm::vec3(scale));
// 3. rotation: add random rotation around a (semi)randomly picked rotation axis vector
float rotAngle = (rand() % 360);
model = glm::rotate(model, rotAngle, glm::vec3(0.4f, 0.6f, 0.8f));
// 4. now add to list of matrices
modelMatrices[i] = model;
}
這段程式碼可能看起來有點嚇人,但我們基本上是沿著一個由 radius 定義的圓圈來變換小行星的 x 和 z 位置,並透過 \-offset 和 offset 隨機地讓每個小行星在圓圈周圍產生一點位移。我們讓 y 方向的位移影響較小,以創建一個更平坦的小行星環。然後我們應用縮放和旋轉變換,並將最終的變換矩陣儲存在大小為 amount 的 modelMatrices 中。在這裡我們為每個小行星產生了 1000 個模型矩陣。
載入行星和岩石模型並編譯一組著色器之後,渲染程式碼看起來會像這樣:
// draw planet
shader.use();
glm::mat4 model = glm::mat4(1.0f);
model = glm::translate(model, glm::vec3(0.0f, -3.0f, 0.0f));
model = glm::scale(model, glm::vec3(4.0f, 4.0f, 4.0f));
shader.setMat4("model", model);
planet.Draw(shader);
// draw meteorites
for(unsigned int i = 0; i < amount; i++)
{
shader.setMat4("model", modelMatrices[i]);
rock.Draw(shader);
}
我們首先繪製行星模型,對其進行平移和縮放以適應場景,然後我們繪製數量等於我們之前產生的變換矩陣 amount 的岩石模型。然而,在我們繪製每一塊岩石之前,我們首先在著色器中設定對應的模型變換矩陣。
結果就是一個類太空的場景,我們可以看到一個圍繞行星、看起來很自然的小行星環:
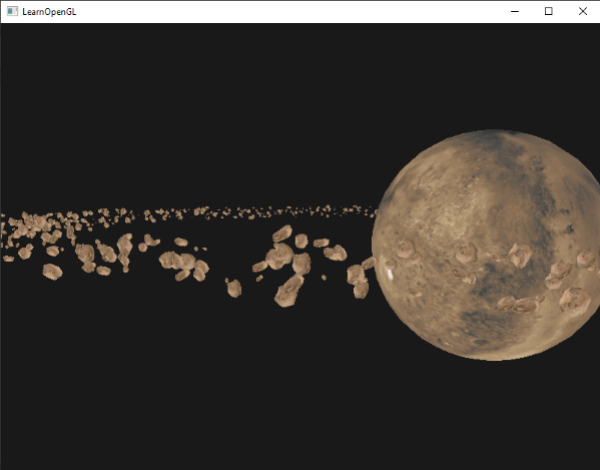
這個場景每幀總共包含 1001 次渲染呼叫,其中 1000 次是岩石模型的。你可以在這裡找到這個場景的原始碼。
一旦我們開始增加這個數字,我們就會很快注意到場景不再流暢運行,並且我們每秒能夠渲染的幀數會急劇減少。一旦我們將 amount 設定為接近 2000,在我們的 GPU 上場景就已經變得非常慢,以至於難以四處移動。
現在讓我們嘗試渲染相同的場景,但這次使用實例化渲染。我們首先需要稍微調整頂點著色器:
#version 330 core
layout (location = 0) in vec3 aPos;
layout (location = 2) in vec2 aTexCoords;
layout (location = 3) in mat4 instanceMatrix;
out vec2 TexCoords;
uniform mat4 projection;
uniform mat4 view;
void main()
{
gl_Position = projection * view * instanceMatrix * vec4(aPos, 1.0);
TexCoords = aTexCoords;
}
我們不再使用 model uniform 變數,而是將 mat4 宣告為頂點屬性,這樣我們就可以儲存一個由變換矩陣組成的實例化陣列。然而,當我們將資料型態宣告為大於 vec4 的頂點屬性時,事情就會有點不同。頂點屬性所允許的最大資料量等於一個 vec4。由於 mat4 本質上是 4 個 vec4,我們必須為這個特定的矩陣保留 4 個頂點屬性。因為我們將其位置設為 3,所以矩陣的各欄將會擁有頂點屬性位置 3、4、5 和 6。
然後我們必須設定這 4 個頂點屬性中的每一個的屬性指標,並將它們配置為實例化陣列:
// vertex buffer object
unsigned int buffer;
glGenBuffers(1, &buffer);
glBindBuffer(GL_ARRAY_BUFFER, buffer);
glBufferData(GL_ARRAY_BUFFER, amount * sizeof(glm::mat4), &modelMatrices[0], GL_STATIC_DRAW);
for(unsigned int i = 0; i < rock.meshes.size(); i++)
{
unsigned int VAO = rock.meshes[i].VAO;
glBindVertexArray(VAO);
// vertex attributes
std::size_t vec4Size = sizeof(glm::vec4);
glEnableVertexAttribArray(3);
glVertexAttribPointer(3, 4, GL_FLOAT, GL_FALSE, 4 * vec4Size, (void*)0);
glEnableVertexAttribArray(4);
glVertexAttribPointer(4, 4, GL_FLOAT, GL_FALSE, 4 * vec4Size, (void*)(1 * vec4Size));
glEnableVertexAttribArray(5);
glVertexAttribPointer(5, 4, GL_FLOAT, GL_FALSE, 4 * vec4Size, (void*)(2 * vec4Size));
glEnableVertexAttribArray(6);
glVertexAttribPointer(6, 4, GL_FLOAT, GL_FALSE, 4 * vec4Size, (void*)(3 * vec4Size));
glVertexAttribDivisor(3, 1);
glVertexAttribDivisor(4, 1);
glVertexAttribDivisor(5, 1);
glVertexAttribDivisor(6, 1);
glBindVertexArray(0);
}
請注意,我們透過將 Mesh 的 VAO 變數宣告為 public 而不是 private,來作弊了一下,這樣我們就可以存取它的頂點陣列物件。這並不是最乾淨的解決方案,但只是一個簡單的修改,以適應這個範例。除了這個小伎倆之外,這段程式碼應該很清楚。我們基本上是在宣告 OpenGL 應該如何為矩陣的每個頂點屬性解釋緩衝區,以及這些頂點屬性中的每一個都是一個實例化陣列。
接著我們再次取出網格的 VAO,這次使用 glDrawElementsInstanced 進行繪製:
// draw meteorites
instanceShader.use();
for(unsigned int i = 0; i < rock.meshes.size(); i++)
{
glBindVertexArray(rock.meshes[i].VAO);
glDrawElementsInstanced(
GL_TRIANGLES, rock.meshes[i].indices.size(), GL_UNSIGNED_INT, 0, amount
);
}
在這裡,我們繪製與前一個範例相同數量的 amount 小行星,但這次是使用實例化渲染。結果應該完全相同,但一旦我們增加 amount,你就會真正開始看到實例化渲染的威力。在沒有實例化渲染的情況下,我們能夠流暢地渲染大約 1000 到 1500 個小行星。使用實例化渲染,我們現在可以將這個值設定為 100000。由於岩石模型有 576 個頂點,這將相當於每幀繪製大約 57 萬個頂點而沒有顯著的性能下降;而且只需要 2 次繪製呼叫!
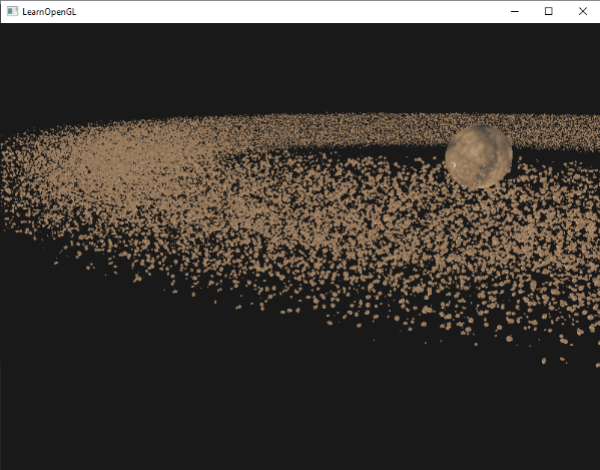
這張圖片是用 100000 個小行星渲染的,半徑為 150.0f,位移等於 25.0f。你可以在這裡找到實例化渲染範例的原始碼。
在不同的機器上,100000 個小行星的數量可能有點太高,所以請嘗試調整這些值,直到達到一個可接受的幀率。
正如你所看到的,在合適的環境類型下,實例化渲染可以對應用程式的渲染能力產生巨大的影響。出於這個原因,實例化渲染通常用於草地、植物、粒子以及像這樣的場景——基本上任何包含許多重複形狀的場景都可以從實例化渲染中受益。
- 1. 介绍
- 2. 开始 • 认识 OpenGL
- 3. 开始 • 创建一个窗口
- 4. 开始 • Hello, 窗口
- 5. 开始 • Hello, 三角形
- 6. 开始 • 著色器
- 7. 开始 • 紋理
- 8. 开始 • 轉換
- 9. 开始 • 座標系統
- 10. 开始 • 相機
- 11. 光 • 顏色
- 12. 光 • 基本光照
- 13. 光 • 材質
- 14. 光 • 光照貼圖
- 15. 光 • 光源
- 16. 光 • 多重光源
- 17. 模型載入 • Assimp
- 18. 模型載入 • Mesh
- 19. 模型載入 • Model
- 20. 高級 OpenGL • 深度測試
- 21. 高級 OpenGL • 模板測試
- 22. 高級 OpenGL • 混合
- 23. 高級 OpenGL • 面剔除
- 24. 高級 OpenGL • Framebuffers
- 25. 高級 OpenGL • Cubemaps
- 26. 高級 OpenGL • 高級 Data
- 27. 高級 OpenGL • 高級 GLSL
- 28. 高級 OpenGL • 實例化
- 29. 高級 OpenGL • Anti-Aliasing
- 30. 高級光照
- 31. 高級光照 • 伽馬矯正
- 32. 高級光照 • 陰影貼圖
- 33. 高級光照 • 點光源陰影
- 34. 高級光照 • 法線貼圖 (Normal Mapping)
- 35. 高級光照 • 視差貼圖(Parallax Mapping)
- 36. 高級光照 • HDR
- 37. 高級光照 • 輝光(Bloom)
- 38. 高級光照 • 延遲著色
- 39. 高級光照 • SSAO
- 40. PBR • 理論
- 41. PBR • 光照
- 42. PBR • 漫射輻照度 (Diffuse-irradiance)
- 43. PBR • Specular-IBL