第二十七章
高級 OpenGL • 高級 GLSL
這一章節不會向你展示什麼超級先進、能夠極大提升場景視覺品質的新功能。這個章節或多或少會深入探討 GLSL 的一些有趣面向,以及一些在未來開發中可能對你有幫助的實用技巧。基本上,這是一些在結合 GLSL 建立 OpenGL 應用程式時,「值得了解」以及「可以讓生活更輕鬆」的功能。
我們會討論一些有趣的 內建變數(built-in variables)、組織著色器輸入與輸出資料的新方法,以及一個非常實用的工具,叫做 uniform 緩衝物件(uniform buffer objects)。
GLSL 的內建變數
著色器是極度管線化的,如果我們需要來自當前著色器以外的任何其他來源的資料,我們就必須傳遞這些資料。我們學會了透過頂點屬性(vertex attributes)、uniforms 和取樣器(samplers)來做到這一點。然而,GLSL 還定義了一些額外的變數,它們以 gl_ 為前綴,為我們提供了額外的途徑來收集或寫入資料。到目前為止,我們已經在之前的章節中看過其中兩個:gl_Position,它是頂點著色器的輸出向量;以及片段著色器的 gl_FragCoord。
我們將討論一些 GLSL 內建的、有趣的輸入與輸出變數,並解釋它們如何能帶給我們好處。請注意,我們不會討論 GLSL 中所有存在的內建變數,所以如果你想看所有內建變數,可以查看 OpenGL 的 wiki。
頂點著色器變數
我們已經看過 gl_Position,它是頂點著色器的剪輯空間(clip-space)輸出位置向量。在頂點著色器中設定 gl_Position 是渲染任何東西到螢幕上的嚴格要求。這沒什麼我們以前沒見過的。
gl_PointSize
我們能夠選擇的渲染圖元(render primitives)之一是 GL_POINTS,在這種情況下,每個單獨的頂點都是一個圖元,並被渲染為一個點。雖然可以透過 OpenGL 的 glPointSize 函式來設定點的大小,但我們也可以在頂點著色器中影響這個值。
GLSL 定義的一個輸出變數叫做 gl_PointSize,它是一個 float 變數,你可以用它來設定點的寬度和高度,單位是像素。透過在頂點著色器中設定點的大小,我們可以對每個頂點的點尺寸進行個別控制。
在頂點著色器中影響點的大小預設是禁用的,但如果你想啟用此功能,你必須啟用 OpenGL 的 GL_PROGRAM_POINT_SIZE:
glEnable(GL_PROGRAM_POINT_SIZE);
一個影響點大小的簡單範例是將點的大小設定為與剪輯空間(clip-space)位置的 Z 值相等,這個 Z 值等於頂點到觀察者的距離。如此一來,當觀察者離頂點越遠,點的大小就應該越大。
void main()
{
gl_Position = projection * view * model * vec4(aPos, 1.0);
gl_PointSize = gl_Position.z;
}
結果就是,當我們離點越遠,我們所繪製的點就會渲染得越大:
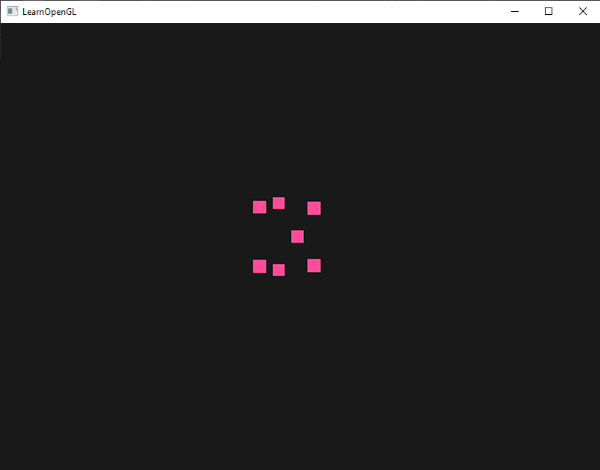
你可以想像,針對每個頂點來改變點的大小,對於像粒子生成這類技術來說是相當有趣的。
gl_VertexID
gl_Position 和 gl_PointSize 是「輸出變數」,因為它們的值是從頂點著色器中被讀取為輸出;我們可以透過對它們寫入來影響結果。頂點著色器也給了我們一個有趣的「輸入變數」,我們只能從中讀取,它叫做 gl_VertexID。
整數變數 gl_VertexID 儲存了我們正在繪製的頂點的當前 ID。當進行「索引繪圖」(indexed rendering)(使用 glDrawElements)時,這個變數儲存了我們正在繪製的頂點的當前索引。當沒有索引繪圖(透過 glDrawArrays)時,這個變數儲存了自渲染呼叫開始以來,當前正在處理的頂點的編號。
片段著色器變數
在片段著色器中,我們也可以存取一些有趣的變數。GLSL 給了我們兩個有趣的輸入變數,叫做 gl_FragCoord 和 gl_FrontFacing。
gl_FragCoord
在討論深度測試(depth testing)時,我們已經看過 gl_FragCoord 幾次了,因為 gl_FragCoord 向量的 z 分量等於該片段的深度值。然而,我們也可以利用該向量的 x 和 y 分量來實現一些有趣的效果。
gl_FragCoord 的 x 和 y 分量是片段的視窗或螢幕空間座標,原點位於視窗的左下角。我們用 glViewport 設定了一個 800x600 的渲染視窗,所以片段的螢幕空間座標的 x 值將介於 0 和 800 之間,而 y 值將介於 0 和 600 之間。
使用片段著色器,我們可以根據片段的螢幕座標來計算不同的顏色值。gl_FragCoord 變數的一個常見用途是比較不同片段計算的視覺輸出,這在技術展示(tech demos)中很常見。例如,我們可以將螢幕一分為二,將一種輸出渲染到視窗的左側,另一種輸出渲染到視窗的右側。下面是一個範例片段著色器,它根據片段的螢幕座標輸出不同的顏色:
void main()
{
if(gl_FragCoord.x < 400)
FragColor = vec4(1.0, 0.0, 0.0, 1.0);
else
FragColor = vec4(0.0, 1.0, 0.0, 1.0);
}
由於視窗的寬度等於 800,因此當一個像素的 x 座標小於 400 時,它必定位於視窗的左側,此時我們會給予該片段一個不同的顏色。
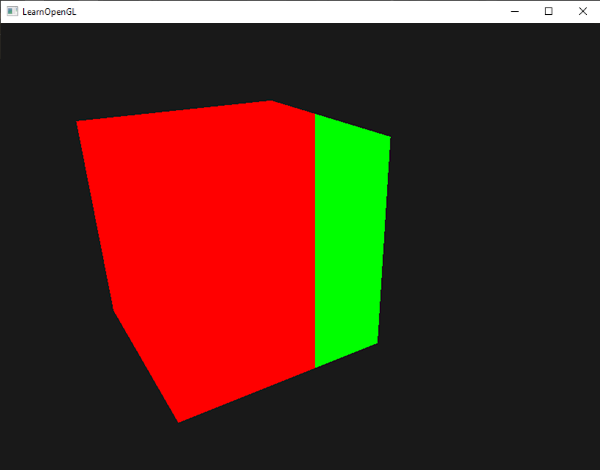
我們現在可以計算出兩種完全不同的片段著色器結果,並將它們各自顯示在視窗的不同側。舉例來說,這對於測試不同的光照技術來說非常棒。
gl_FrontFacing
在片段著色器中,另一個有趣的輸入變數是 gl_FrontFacing 變數。在面剔除的章節中,我們提到 OpenGL 能夠根據頂點的環繞順序來判斷一個面是正面還是反面。gl_FrontFacing 變數告訴我們當前的片段是正面還是反面的一部分。舉例來說,我們可以決定為所有的反面輸出不同的顏色。
gl_FrontFacing 變數是一個 bool 類型,如果片段是正面的一部分,它就是 true,否則就是 false。我們可以用這種方式建立一個立方體,它的內部和外部有不同的紋理:
#version 330 core
out vec4 FragColor;
in vec2 TexCoords;
uniform sampler2D frontTexture;
uniform sampler2D backTexture;
void main()
{
if(gl_FrontFacing)
FragColor = texture(frontTexture, TexCoords);
else
FragColor = texture(backTexture, TexCoords);
}
如果我們往容器內部看,現在就能看到使用了不同的紋理。
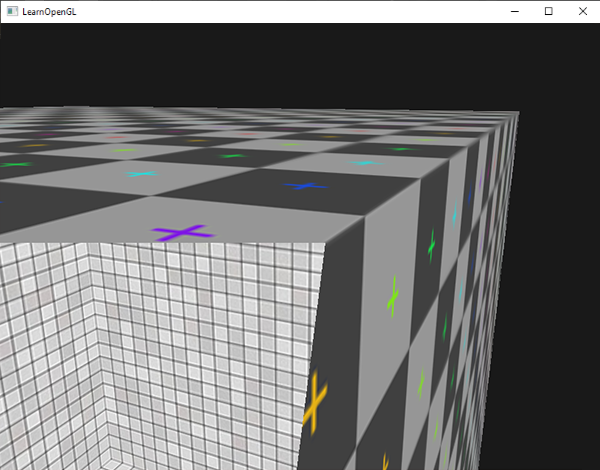
請注意,如果你啟用了面剔除(face culling),你將無法看到容器內部的任何面,因此使用 gl_FrontFacing 將會變得毫無意義。
gl_FragDepth
輸入變數 gl_FragCoord 是一個輸入變數,它讓我們能夠讀取螢幕空間座標並獲得當前片段的深度值,但它是一個「唯讀」(read-only)變數。我們無法影響片段的螢幕空間座標,但可以設定片段的深度值。GLSL 給了我們一個叫做 gl_FragDepth 的輸出變數,我們可以用它在著色器內手動設定片段的深度值。
要在著色器中設定深度值,我們將任何介於 0.0 和 1.0 之間的值寫入此輸出變數:
gl_FragDepth = 0.0; // this fragment now has a depth value of 0.0
如果著色器沒有向 gl_FragDepth 寫入任何內容,這個變數將會自動從 gl_FragCoord.z 取值。
然而,手動設定深度值有一個主要的缺點。那就是一旦我們在片段著色器中寫入 gl_FragDepth,OpenGL 就會停用「早期深度測試」(early depth testing)(這在深度測試章節中討論過)。停用的原因是,OpenGL 在執行片段著色器「之前」無法知道片段將會有什麼深度值,因為片段著色器實際上可能會改變這個值。
透過寫入 gl_FragDepth,你應該將這種效能損失考慮在內。然而,從 OpenGL 4.2 開始,我們可以透過在片段著色器的頂部用「深度條件」(depth condition)重新宣告 gl_FragDepth 變數來在兩者之間進行協調:
layout (depth_<condition>) out float gl_FragDepth;
這個 condition 可以採用以下值:
| 條件 | 描述 |
|---|---|
any | The default value. Early depth testing is disabled. |
greater | You can only make the depth value larger compared to gl_FragCoord.z. |
less | You can only make the depth value smaller compared to gl_FragCoord.z. |
unchanged | If you write to gl_FragDepth, you will write exactly gl_FragCoord.z. |
透過將 greater 或 less 指定為深度條件,OpenGL 可以假設你只會寫入比片段深度值更大或更小的值。這樣一來,當深度緩衝區的值朝著 gl_FragCoord.z 的另一個方向時,OpenGL 仍然能夠進行早期深度測試。
下面顯示了一個片段著色器,其中我們在片段著色器中增加了深度值,但仍希望保留部分早期深度測試功能:
#version 420 core // note the GLSL version!
out vec4 FragColor;
layout (depth_greater) out float gl_FragDepth;
void main()
{
FragColor = vec4(1.0);
gl_FragDepth = gl_FragCoord.z + 0.1;
}
請注意,此功能僅在 OpenGL 4.2 或更高版本中可用。
介面區塊(Interface blocks)
到目前為止,每次我們從頂點著色器傳送資料到片段著色器時,我們都宣告了幾個相匹配的輸入/輸出變數。一次宣告一個變數是將資料從一個著色器傳送到另一個著色器最簡單的方式,但隨著應用程式變得越來越大,你可能會希望傳送的變數不只幾個。
為了幫助我們組織這些變數,GLSL 提供了「介面區塊」(interface blocks)功能,讓我們能夠將變數分組在一起。這種介面區塊的宣告方式非常像 struct 的宣告,不同之處在於它是使用 in 或 out 關鍵字來宣告,取決於該區塊是輸入區塊還是輸出區塊。
#version 330 core
layout (location = 0) in vec3 aPos;
layout (location = 1) in vec2 aTexCoords;
uniform mat4 model;
uniform mat4 view;
uniform mat4 projection;
out VS_OUT
{
vec2 TexCoords;
} vs_out;
void main()
{
gl_Position = projection * view * model * vec4(aPos, 1.0);
vs_out.TexCoords = aTexCoords;
}
這次我們宣告了一個名為 vs_out 的介面區塊,它將所有我們想傳送到下一個著色器的輸出變數組合在一起。這是一個有點瑣碎的範例,但你可以想像這有助於組織著色器的輸入/輸出。當我們想將著色器輸入/輸出分組為陣列時,這也很有用,我們會在下一章關於幾何著色器(geometry shaders)的內容中看到這一點。
然後,我們還需要在下一個著色器(也就是片段著色器)中宣告一個輸入介面區塊。片段著色器中的「區塊名稱」(VS_OUT)應該要與頂點著色器相同,但「實例名稱」(instance name)(在頂點著色器中使用的 vs_out)可以是我們喜歡的任何名稱——避免像 vs_out 這樣容易混淆的名稱,用來表示一個包含輸入值的片段結構。
#version 330 core
out vec4 FragColor;
in VS_OUT
{
vec2 TexCoords;
} fs_in;
uniform sampler2D texture;
void main()
{
FragColor = texture(texture, fs_in.TexCoords);
}
只要兩個介面區塊的名稱相等,它們對應的輸入和輸出就會匹配在一起。這是另一個有用的功能,有助於組織你的程式碼,並且在跨越某些著色器階段(如幾何著色器)時會非常實用。
Uniform 緩衝物件
我們使用 OpenGL 已經有一段時間了,學到了一些非常酷的技巧,但也遇到了一些惱人的地方。舉例來說,當使用多個著色器時,我們必須不斷地設定 uniform 變數,而其中大部分對於每個著色器來說都是完全相同的。
OpenGL 給了我們一個叫做 uniform 緩衝物件 的工具,它允許我們宣告一組「全域」(global)uniform 變數,這些變數在任何數量的著色器程式中都保持不變。當使用 uniform 緩衝物件時,我們只需要在固定的 GPU 記憶體中一次性設定相關的 uniforms。我們仍然需要手動設定每個著色器獨有的 uniforms。不過,建立和配置一個 uniform 緩衝物件需要一些工作。
因為 uniform 緩衝物件就像任何其他緩衝區一樣,我們可以透過 glGenBuffers 函式來建立一個,將它綁定到 GL_UNIFORM_BUFFER 緩衝區目標,然後將所有相關的 uniform 資料儲存到緩衝區中。關於 uniform 緩衝物件的資料應該如何儲存,有一些特定的規則,我們稍後會討論。首先,我們將使用一個簡單的頂點著色器,並將我們的 projection 和 view 矩陣儲存在一個所謂的「uniform 區塊」(uniform block)中:
#version 330 core
layout (location = 0) in vec3 aPos;
layout (std140) uniform Matrices
{
mat4 projection;
mat4 view;
};
uniform mat4 model;
void main()
{
gl_Position = projection * view * model * vec4(aPos, 1.0);
}
在我們大多數的範例中,我們為每個著色器在每一幀都設定一個投影(projection)和觀察(view)uniform 矩陣。這正是 uniform 緩衝物件變得有用的完美範例,因為現在我們只需要儲存這些矩陣一次。
在這裡,我們宣告了一個名為 Matrices 的 uniform 區塊,它儲存了兩個 4x4 矩陣。uniform 區塊中的變數可以直接存取,無需加上區塊名稱作為前綴。然後,我們在 OpenGL 程式碼的某個地方將這些矩陣值儲存在一個緩衝區中,每個宣告了這個 uniform 區塊的著色器都可以存取這些矩陣。
你現在可能想知道 layout (std140) 語句是什麼意思。這句話的意思是,當前定義的 uniform 區塊使用特定的記憶體佈局來儲存其內容;這個語句設定了「uniform 區塊佈局」(uniform block layout)。
Uniform 區塊佈局
uniform 區塊的內容儲存在一個緩衝區物件中,這實際上不過是一塊預留的 GPU 全域記憶體。因為這塊記憶體沒有關於它所儲存資料類型的資訊,我們需要告訴 OpenGL 哪一部分的記憶體對應於著色器中的哪個 uniform 變數。
想像一下著色器中有以下 uniform 區塊:
layout (std140) uniform ExampleBlock
{
float value;
vec3 vector;
mat4 matrix;
float values[3];
bool boolean;
int integer;
};
我們想知道的是這些變數的(以位元組為單位的)大小,以及每個變數的偏移量(從區塊開頭算起),這樣我們才能按它們各自的順序將它們放入緩衝區中。每個元素的大小在 OpenGL 中有明確規定,並直接對應於 C++ 資料類型;向量和矩陣則是(大型)浮點數陣列。OpenGL 沒有明確說明的是變數之間的「間距」(spacing)。這讓硬體可以根據其需要來定位或填充變數。舉例來說,硬體能夠將一個 vec3 緊鄰一個 float 放置。並非所有硬體都能處理這種情況,它會先將 vec3 填充為一個 4 個浮點數的陣列,然後再附加 float。這是一個很棒的功能,但對我們來說很不方便。
預設情況下,GLSL 使用一種叫做 shared 佈局的 uniform 記憶體佈局——之所以叫做 shared(共享),是因為一旦偏移量由硬體定義後,它們就會在多個程式之間保持一致的「共享」。使用 shared 佈局時,只要變數的順序保持不變,GLSL 就可以為了最佳化而重新定位 uniform 變數。由於我們不知道每個 uniform 變數的偏移量是多少,我們就無法確切地知道如何精確地填寫我們的 uniform 緩衝區。雖然我們可以使用 glGetUniformIndices 等函式來查詢這些資訊,但這不是我們在本章要採用的方法。
雖然 shared 佈局為我們提供了一些節省空間的最佳化,但我們需要查詢每個 uniform 變數的偏移量,這會帶來大量的工作。然而,一般的做法是不用 shared 佈局,而是使用 std140 佈局。std140 佈局透過標準化每個變數類型的偏移量來明確地規定了它們的記憶體佈局,這些偏移量受一套規則所約束。因為這是標準化的,我們可以手動計算出每個變數的偏移量。
每個變數都有一個「基本對齊」(base alignment),它等於一個變數在使用 std140 佈局規則的 uniform 區塊中佔用的空間(包括填充)。對於每個變數,我們計算它的「對齊偏移量」(aligned offset):從區塊開始處算起的變數位元組偏移量。變數的對齊位元組偏移量必須是其基本對齊的倍數。這聽起來有點饒口,但我們很快就會看到一些範例來澄清這點。
確切的佈局規則可以在 OpenGL 的 uniform 緩衝區規範中找到這裡,但我們會在下面列出最常見的規則。每個 GLSL 中的變數類型,如 int、float 和 bool,都被定義為四位元組量,每個 4 位元組實體表示為 N。
| Type | Layout rule |
|---|---|
| Scalar e.g. | Each scalar has a base alignment of N. |
| Vector | Either 2N or 4N. This means that a |
| Array of scalars or vectors | Each element has a base alignment equal to that of a |
| Matrices | Stored as a large array of column vectors, where each of those vectors has a base alignment of |
| Struct | Equal to the computed size of its elements according to the previous rules, but padded to a multiple of the size of a |
如同大多數的 OpenGL 規範一樣,透過範例來理解會更容易。我們將使用前面介紹的 ExampleBlock uniform 區塊,並使用 std140 佈局來計算其每個成員的對齊偏移量:
layout (std140) uniform ExampleBlock
{
// base alignment // aligned offset
float value; // 4 // 0
vec3 vector; // 16 // 16 (offset must be multiple of 16 so 4->16)
mat4 matrix; // 16 // 32 (column 0)
// 16 // 48 (column 1)
// 16 // 64 (column 2)
// 16 // 80 (column 3)
float values[3]; // 16 // 96 (values[0])
// 16 // 112 (values[1])
// 16 // 128 (values[2])
bool boolean; // 4 // 144
int integer; // 4 // 148
};
作為一個練習,試著自己計算偏移量,然後與這張表格進行比較。有了這些根據 std140 佈局規則計算出的偏移量,我們就可以使用像 glBufferSubData 這樣的函式,將資料填充到緩衝區中適當的偏移位置。雖然這不是最高效的方法,但 std140 佈局確實保證了在每個宣告了這個 uniform 區塊的程式中,記憶體佈局都保持一致。
透過在 uniform 區塊的定義中加入 layout (std140) 語句,我們告訴 OpenGL 這個 uniform 區塊使用 std140 佈局。還有另外兩種佈局可以選擇,它們要求我們在填充緩衝區之前查詢每個偏移量。我們已經看過 shared 佈局,而另一種剩下的佈局是 packed。當使用 packed 佈局時,無法保證佈局在程式之間保持一致(不共享),因為它允許編譯器將 uniform 變數從 uniform 區塊中最佳化掉,這在不同的著色器之間可能會有所不同。
使用 uniform 緩衝區
我們已經定義了 uniform 區塊並指定了它們的記憶體佈局,但我們還沒有討論如何實際使用它們。
首先,我們需要建立一個 uniform 緩衝區物件,這透過熟悉的 glGenBuffers 來完成。一旦我們有了緩衝區物件,我們就將它綁定到 GL_UNIFORM_BUFFER 目標,並呼叫 glBufferData 來分配足夠的記憶體。
unsigned int uboExampleBlock;
glGenBuffers(1, &uboExampleBlock);
glBindBuffer(GL_UNIFORM_BUFFER, uboExampleBlock);
glBufferData(GL_UNIFORM_BUFFER, 152, NULL, GL_STATIC_DRAW); // allocate 152 bytes of memory
glBindBuffer(GL_UNIFORM_BUFFER, 0);
現在,無論何時我們想更新或插入資料到緩衝區中,我們就綁定到 uboExampleBlock 並使用 glBufferSubData 來更新它的記憶體。我們只需要更新這個 uniform 緩衝區一次,所有使用這個緩衝區的著色器現在都會使用它的最新資料。但是,OpenGL 怎麼知道哪個 uniform 緩衝區對應哪個 uniform 區塊呢?
在 OpenGL 的上下文中,定義了一些「綁定點」(binding points),我們可以將 uniform 緩衝區連結到這些綁定點上。一旦我們建立了一個 uniform 緩衝區,我們就將它連結到其中一個綁定點,同時我們也將著色器中的 uniform 區塊連結到相同的綁定點,從而有效地將它們連結在一起。下面的圖表說明了這一點:
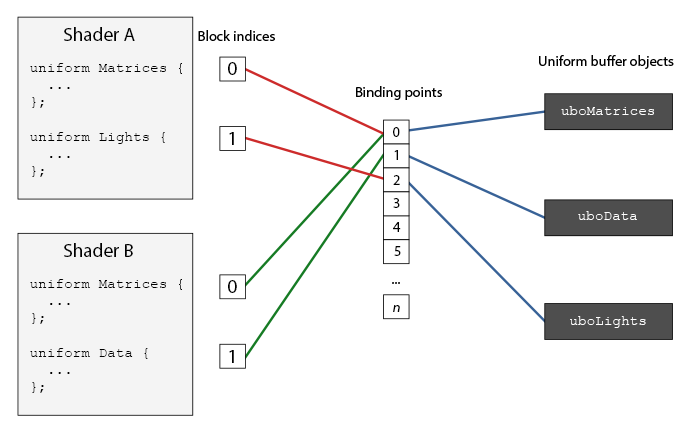
如你所見,我們可以將多個 uniform 緩衝區綁定到不同的綁定點。因為著色器 A 和著色器 B 都將一個 uniform 區塊連結到相同的綁定點 0,它們的 uniform 區塊共享了在 uboMatrices 中找到的相同 uniform 資料;前提是兩個著色器都定義了相同的 Matrices uniform 區塊。
要將著色器的 uniform 區塊設定到特定的綁定點,我們呼叫 glUniformBlockBinding,它接受一個程式物件、一個 uniform 區塊索引,以及要連結到的綁定點。uniform 區塊索引 是著色器中定義的 uniform 區塊的位置索引。這可以透過呼叫 glGetUniformBlockIndex 來取得,它接受一個程式物件和 uniform 區塊的名稱。我們可以將圖表中的 Lights uniform 區塊設定到綁定點 2,如下所示:
unsigned int lights_index = glGetUniformBlockIndex(shaderA.ID, "Lights");
glUniformBlockBinding(shaderA.ID, lights_index, 2);
請注意,我們必須為每個著色器重複這個過程。
從 OpenGL 4.2 版開始,也可以透過在著色器中加入另一個佈局指定符(layout specifier),來明確地儲存 uniform 區塊的綁定點,從而省去了呼叫 glGetUniformBlockIndex 和 glUniformBlockBinding 的麻煩。以下程式碼明確地設定了 Lights uniform 區塊的綁定點:
layout(std140, binding = 2) uniform Lights { ... };
然後我們還需要將 uniform 緩衝區物件綁定到相同的綁定點,這可以透過 glBindBufferBase 或 glBindBufferRange 來實現。
glBindBufferBase(GL_UNIFORM_BUFFER, 2, uboExampleBlock);
// or
glBindBufferRange(GL_UNIFORM_BUFFER, 2, uboExampleBlock, 0, 152);
glBindbufferBase 函式需要一個目標(target)、一個綁定點索引(binding point index)和一個 uniform 緩衝區物件。這個函式將 uboExampleBlock 連結到綁定點 2;從這一刻起,綁定點的兩端都連結起來了。你也可以使用 glBindBufferRange,它需要額外的偏移量和大小參數——透過這種方式,你可以只將 uniform 緩衝區的一個特定範圍綁定到一個綁定點。使用 glBindBufferRange,你可以將多個不同的 uniform 區塊連結到一個 uniform 緩衝區物件。
現在所有設定都已完成,我們可以開始向 uniform 緩衝區中添加資料了。我們可以將所有資料作為一個單一的位元組陣列添加,或者隨時使用 glBufferSubData 更新緩衝區的部分內容。要更新 boolean 這個 uniform 變數,我們可以如下更新 uniform 緩衝區物件:
glBindBuffer(GL_UNIFORM_BUFFER, uboExampleBlock);
int b = true; // bools in GLSL are represented as 4 bytes, so we store it in an integer
glBufferSubData(GL_UNIFORM_BUFFER, 144, 4, &b);
glBindBuffer(GL_UNIFORM_BUFFER, 0);
同樣的程序也適用於 uniform 區塊內的所有其他 uniform 變數,只是範圍參數不同。
一個簡單的範例
那麼,讓我們來展示一個 uniform 緩衝物件的實際範例。如果我們回顧所有之前的程式碼範例,我們會發現我們一直在使用 3 個矩陣:投影(projection)、觀察(view)和模型(model)矩陣。在這些矩陣中,只有模型矩陣會頻繁變化。如果我們有多個著色器使用這組相同的矩陣,使用 uniform 緩衝物件可能會更好。
我們將把投影和觀察矩陣儲存在一個名為 Matrices 的 uniform 區塊中。我們不會把模型矩陣儲存在裡面,因為模型矩陣在著色器之間變化頻繁,所以我們從 uniform 緩衝物件中得不到什麼好處。
#version 330 core
layout (location = 0) in vec3 aPos;
layout (std140) uniform Matrices
{
mat4 projection;
mat4 view;
};
uniform mat4 model;
void main()
{
gl_Position = projection * view * model * vec4(aPos, 1.0);
}
這裡沒什麼特別的,除了我們現在使用了帶有 std140 佈局的 uniform 區塊。在我們的範例應用程式中,我們將會顯示 4 個立方體,每個立方體都使用不同的著色器程式來顯示。這 4 個著色器程式都使用相同的頂點著色器,但每個都有一個獨特的片段著色器,只輸出一個單獨的顏色,且這個顏色在不同的著色器之間是不同的。
首先,我們將頂點著色器的 uniform 區塊設定為綁定點 0。請注意,我們必須為每個著色器都這樣做:
unsigned int uniformBlockIndexRed = glGetUniformBlockIndex(shaderRed.ID, "Matrices");
unsigned int uniformBlockIndexGreen = glGetUniformBlockIndex(shaderGreen.ID, "Matrices");
unsigned int uniformBlockIndexBlue = glGetUniformBlockIndex(shaderBlue.ID, "Matrices");
unsigned int uniformBlockIndexYellow = glGetUniformBlockIndex(shaderYellow.ID, "Matrices");
glUniformBlockBinding(shaderRed.ID, uniformBlockIndexRed, 0);
glUniformBlockBinding(shaderGreen.ID, uniformBlockIndexGreen, 0);
glUniformBlockBinding(shaderBlue.ID, uniformBlockIndexBlue, 0);
glUniformBlockBinding(shaderYellow.ID, uniformBlockIndexYellow, 0);
接下來,我們建立實際的 uniform 緩衝區物件,並將該緩衝區綁定到綁定點 0:
unsigned int uboMatrices
glGenBuffers(1, &uboMatrices);
glBindBuffer(GL_UNIFORM_BUFFER, uboMatrices);
glBufferData(GL_UNIFORM_BUFFER, 2 * sizeof(glm::mat4), NULL, GL_STATIC_DRAW);
glBindBuffer(GL_UNIFORM_BUFFER, 0);
glBindBufferRange(GL_UNIFORM_BUFFER, 0, uboMatrices, 0, 2 * sizeof(glm::mat4));
首先,我們為緩衝區分配足夠的記憶體,它等於 glm::mat4 的 2 倍大小。GLM 的矩陣類型大小直接對應於 GLSL 中的 mat4。然後,我們將緩衝區的一個特定範圍(在本例中是整個緩衝區)連結到綁定點 0。
現在,剩下的就是填充緩衝區了。如果我們保持投影矩陣的「視角」(field of view)值不變(所以不再有相機縮放),我們只需在應用程式中更新它一次——這也意味著我們只需將它插入緩衝區一次。因為我們已經在緩衝區物件中分配了足夠的記憶體,我們可以在進入渲染迴圈之前使用 glBufferSubData 來儲存投影矩陣:
glm::mat4 projection = glm::perspective(glm::radians(45.0f), (float)width/(float)height, 0.1f, 100.0f);
glBindBuffer(GL_UNIFORM_BUFFER, uboMatrices);
glBufferSubData(GL_UNIFORM_BUFFER, 0, sizeof(glm::mat4), glm::value_ptr(projection));
glBindBuffer(GL_UNIFORM_BUFFER, 0);
在這裡,我們用投影矩陣儲存了 uniform 緩衝區的前半部分。然後,在每一幀渲染物件之前,我們用觀察矩陣更新緩衝區的後半部分:
glm::mat4 view = camera.GetViewMatrix();
glBindBuffer(GL_UNIFORM_BUFFER, uboMatrices);
glBufferSubData(GL_UNIFORM_BUFFER, sizeof(glm::mat4), sizeof(glm::mat4), glm::value_ptr(view));
glBindBuffer(GL_UNIFORM_BUFFER, 0);
Uniform 緩衝物件的部分就到此為止了。現在,每個包含 Matrices uniform 區塊的頂點著色器都會包含儲存在 uboMatrices 中的資料。所以,如果我們現在使用 4 個不同的著色器來繪製 4 個立方體,它們的投影和觀察矩陣應該是相同的:
glBindVertexArray(cubeVAO);
shaderRed.use();
glm::mat4 model = glm::mat4(1.0f);
model = glm::translate(model, glm::vec3(-0.75f, 0.75f, 0.0f)); // move top-left
shaderRed.setMat4("model", model);
glDrawArrays(GL_TRIANGLES, 0, 36);
// ... draw Green Cube
// ... draw Blue Cube
// ... draw Yellow Cube
我們唯一仍然需要設定的 uniform 是 model uniform。在這種情況下使用 uniform 緩衝物件可以為我們每個著色器省下不少 uniform 呼叫。結果看起來像這樣:

每個立方體都透過平移模型矩陣被移到視窗的一側,並且由於片段著色器不同,它們的顏色在每個物件上都不同。這是一個使用 uniform 緩衝物件的相對簡單情境,但任何大型渲染應用程式都可能有多達數百個著色器程式處於活動狀態,這就是 uniform 緩衝物件真正開始大放異彩的地方。
你可以在這裡找到 uniform 範例應用程式的完整原始碼。
Uniform 緩衝物件相對於單一 uniform 有幾個優點。首先,一次設定大量的 uniforms 比一個一個設定要快得多。其次,如果你想在多個著色器中更改同一個 uniform,在 uniform 緩衝區中更改一次要容易得多。最後一個優點雖然不那麼明顯,但就是使用 uniform 緩衝物件時,你可以在著色器中使用多得多的 uniforms。OpenGL 對它可以處理的 uniform 資料量有限制,可以用 GL_MAX_VERTEX_UNIFORM_COMPONENTS 查詢。當使用 uniform 緩衝物件時,這個限制要高得多。所以,無論何時你達到最大 uniform 數量(例如在進行骨骼動畫時),總有 uniform 緩衝物件可以幫你。
- 1. 介绍
- 2. 开始 • 认识 OpenGL
- 3. 开始 • 创建一个窗口
- 4. 开始 • Hello, 窗口
- 5. 开始 • Hello, 三角形
- 6. 开始 • 著色器
- 7. 开始 • 紋理
- 8. 开始 • 轉換
- 9. 开始 • 座標系統
- 10. 开始 • 相機
- 11. 光 • 顏色
- 12. 光 • 基本光照
- 13. 光 • 材質
- 14. 光 • 光照貼圖
- 15. 光 • 光源
- 16. 光 • 多重光源
- 17. 模型載入 • Assimp
- 18. 模型載入 • Mesh
- 19. 模型載入 • Model
- 20. 高級 OpenGL • 深度測試
- 21. 高級 OpenGL • 模板測試
- 22. 高級 OpenGL • 混合
- 23. 高級 OpenGL • 面剔除
- 24. 高級 OpenGL • Framebuffers
- 25. 高級 OpenGL • Cubemaps
- 26. 高級 OpenGL • 高級 Data
- 27. 高級 OpenGL • 高級 GLSL
- 28. 高級 OpenGL • 實例化
- 29. 高級 OpenGL • Anti-Aliasing
- 30. 高級光照
- 31. 高級光照 • 伽馬矯正
- 32. 高級光照 • 陰影貼圖
- 33. 高級光照 • 點光源陰影
- 34. 高級光照 • 法線貼圖 (Normal Mapping)
- 35. 高級光照 • 視差貼圖(Parallax Mapping)
- 36. 高級光照 • HDR
- 37. 高級光照 • 輝光(Bloom)
- 38. 高級光照 • 延遲著色
- 39. 高級光照 • SSAO
- 40. PBR • 理論
- 41. PBR • 光照
- 42. PBR • 漫射輻照度 (Diffuse-irradiance)
- 43. PBR • Specular-IBL